Digital Twins

SIRIUS held a one-day workshop on Digital Twins in Oslo on 20th March 2018. This brought together participants from Equinor, Petrobras, Schlumberger, Halliburton, DNV GL, Computas, OSISoft, Aker Solutions, Aibel, IBM and SAP. Participants shared their ideas of what a digital twin is and should be. The results of this workshop were published at the Scandinavian Simulation Conference in September. They are also summarised here.
The digital twin remained an industry buzzword in 2018. Gartner group identified digital twins as one of the top ten strategic technology trends for both 2017 and 2018 and then placed the idea at the very top of their hype curve for 2018. What do we mean by a digital twin? The idea may have its origin in NASA, with roots back into the Apollo program. The US Government defines a twin as “An integrated multi-physics, multi-scale, probabilistic simulation of an as-built system … that uses the best available models, sensor information, and input data to mirror and predict activities/performance over the life of its corresponding physical twin”. Put simply, a twin is a digital replica of a physical object or system.
Digital twins build on the idea that digitalisation can use models of products and processes with sensor data to improve operational decisions and enhance products. SIRIUS agrees. This trend is a mainstreaming and maturing of decades of work in simulation, model-based control and computer-aided design. Recently, vendors have been bringing to market digital twins that build on their specific expertise and products. Thus, simulation vendors refine their on-line simulators. CAD suppliers build virtual reality based on design models. Product and system vendors bring their design and analysis models on line. Control and database vendors offer integration platforms for twins, as do database and ERP suppliers. A facility owner faces the challenge of building a useful and sustainable digital twin from a multitude of competing, partial and inconsistent solutions. How can we increase the speed of implementation of these systems? How can we reduce system cost? How can we achieve interoperability between systems so that they support interdisciplinary decision making? How can we avoid overwhelming users with complexity?
How can digital twins be made sustainable, maintainable and useful despite these challenges? We believe that a solution will collaboration between computer scientists, control and simulation engineers, data scientists and end-user technical specialists. Here we will present the computer science and data science parts of solution. This research program combines the sub-disciplines of knowledge representation, natural language technologies, formal methods, scalable computing and data science. This knowledge of technologies must be informed by the deep domain knowledge that is embedded in the digital twins’ simulation models and is owned by a facility’s engineers, operators and managers.
We must use a semantic backbone that supports the integration of several different digital twin applications around a shared understanding of a facility’s design. This backbone will need to find a pragmatic balance between comprehensiveness and maintainability. It will also need to build on standards in a way that prevents reinvention of the wheel and allows modular construction of semantic models. SIRIUS’ recent advances in the construction of ontologies using templates promise to allow this.
Simulation providers can use these ontologies to exchange model configurations with engineering databases and the calculated results with the monitoring and optimization layers of the digital twins. Point-to-point connections through tag cross-reference lists can be replaced with declarative mappings – where data in the simulation results or configuration is mapped to items in the semantic backbone.
Good semantic models can also address the usability problems. Mapping data to concepts that are used by the end-user allows automatic generation of graphical interfaces that meet a specific user’s needs. SIRIUS’ OptiqueVQS framework is just such a tool.
A successful digital twin needs correlation of data from designs, measurements and simulations with text from logs and documents. There are now many commercial and academic tools for parsing and processing text. The IBM Watson framework is one such commercial offering. However, language algorithms that are trained on general data sets do not perform well when confronted with oil and gas terminology. SIRIUS centre is working on this domain adaption challenge, with promising results and good performance in solving standard challenge problems.
Challenges of maintenance and computational overload can also be addressed through using formal methods to design and monitor the deployment of a digital twin. As we noted above, a digital twin is a collection of interacting computational components, deployed across one or more cloud platforms and including edge devices. The behaviour of this system is difficult to predict, especially at design time. However, SIRIUS’ ABS simulation tool for the computer systems themselves can be used to test different deployment plans and resolve challenges. The same model can also be used as a monitoring tool for the deployed system – a digital twin of the digital twin.
We will combine these simulations with stronger analyses to generate solutions and verify their correctness with respect to requirements such as resource restrictions, safety regulations, and space limitations. This long-term perspective is illustrated by the following diagram, which shows the current work (in black) and some possible directions that can be explored (in red) to extend the current case study; these future directions provide concrete scientific challenges as well as added value in the planning processes.
Finally, there remains the challenge of uncertainty, validation and data science. The digital twin is built on models. To quote George Box (Box, 1979), all these models are wrong, but some are useful. A digital twin will contain many models. Some will be based on physical principles: structural, geometrical and process simulations. Others will be purely empirical, based on machine learning. These models must be validated against observed facility behaviour and aligned so that they mirror observed normal behaviour. Aligning models to observed data is difficult and remains an art. Finding out whether a discrepancy is due to an error in data, a wrong parameter, poor model structure or an actual malfunction in the facility requires a good understanding of the facility and well-developed judgment. This is true whether the models a rigorous physical model or a machine-learnt empirical representation.
A maintainable digital twin will contain structured tools that allow validation and tuning of all the models in the system. We believe that hybrid analytics – the combination of data science with physical and engineering simulations – is a valuable and fruitful area of research. Machine learning can benefit from being constrained by the laws of physics, while the laws of physics contain parameters that are uncertain or expensive to measure. Good statistical practice is needed in the engineering communities and engineering knowledge is needed among data scientists.
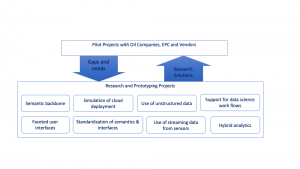
We are working on two projects related to data science for digital twins. The first of these is related to data access. Data science projects in industry are currently not scalable. Each new implementation needs to start from scratch, finding data, checking it and making it available. Our proposed semantic backbone will allow data science solutions to be rapidly transferred to similar sites in an organization.
The second area of research is related to the use of sensor data in data science. When a data scientist talks about streaming data, they usually mean a sequence of discrete event records – like tweets or sales transactions. The stream of data from analogue sensors is subtly different. The underlying signal from a sensor is continuous. The process of digitization itself introduces uncertainty and error in the calculation. Filtering and data compression provide further sources for error. Common data science frameworks expect data in vectors at common times. Production of this from a time series data base requires interpolation. All these details increase the cost and decrease the usefulness of data science work. A well-defined semantics and query tool for time-series data from sensors could solve many of these challenges.
Companies in the oil and gas sector are installing digital twins now, using commercially available platforms and siloed applications. We have an opportunity to engage with the observed problems of our colleagues in operations and maintenance through pilots.
Each pilot has a narrow enough focus to be doable. The companies we are collaborating with have linked these installations to a well-defined business case. Current pilots are ambitious: if successful they will bring previously unachieved levels of interdisciplinarity, effectiveness and access to data in design, operation and maintenance. At the same time, the pilots are focused on one specific business problem. By working with existing pilots and proposing new pilots we plan to establish a virtuous cycle, where shortcomings in today’s technology and methods can be filled with research-driven innovations.
More information and news from this beacon
Projects in the Digital Twins beacon
(click on the Project Name to read more about project)
Analysis of Digital Twins
Digital Twins Project Development and Laboratory [more information coming soon]
Sustainable and Maintainable Digital Twins [more information coming soon]
Facility Digital Twins [more information coming soon]
Digital Twins in Manufacturing [more information coming soon]
SIRIUS Researchers
- David Cameron
- Evgeny Kharmalov
- Arild Waaler
- Roar Fjellheim – Computas
- Francisco Martin-Recuerda – DNV GL
- Brandon Perry – OSIsoft